'Linux'에 해당되는 글 10건
- 2007.08.08 [펌] Linux 정리 #2
- 2007.08.08 [펌] Linux 정리 #1
- 2007.07.25 [펌]MySql 복구 방법
- 2007.07.25 [펌]MySQL Cluster
일단 ls의 절대경로를 알아야 한다. which ls
which로 알아낸 ls의 절대경로로 rpm질의를 한다.rpm -qf /bin/ls
[root@piruks /etc]# which ls
/bin/ls
[root@piruks /etc]# rpm -qf /bin/ls
fileutils-4.0i-2mz
현재 rpm패키지의 의존패키지
rpm -qR 패키지명
현재 디렉토리크기
du -h --max-depth=1 .
바로 이전 디렉토리로 가기
cd -
프로세스명으로 프로세스 죽이기
[리눅스]
killall 프로세스명
kill -9 `pidof 프로세스명`
하드웨어 시계맞추기
배포본을 설치하고 나면 시간이 맞지 않는 경우가 많다.
간단히 어느정도 정확한 시간을 설정하는 방법이다.
[root@dev /down]# rdate -s time.kriss.re.kr
[root@dev /down]# clock -w
원격에서 리모트서버의 X application실행시
X윈도 app를 실행할때 다음과 같은 에러가 나면 조치
[kang@dev /home/kang] xclock
Xlib: connection to "211.222.186.170:0.0" refused by server
Xlib: Client is not authorized to connect to Server
Error: Can't open display: 211.222.186.170:0.0
export DISPLAY=211.222.186.170:0
xhost +211.222.186.170
파일내 문자열 치환
mysql에 replace라는 프로그램이 딸려있다.
현재 디렉토리내 모든 파일에서 a를 b로 변경
replace a b -- *
현재 디렉토리내 모든 파일에서 a는 b로, b는 a로 변경
replace a b b a -- *
하위 디렉토리를 포함하여 위의 작업을 할때
replace a b -- `find . -type f -name '*' -print`
or
find . -type f -name '*' -exec replace a b -- {} ;
PERL로 한다면 다음과 같이 해도 된다.
find . -type f -name '*' -exec perl -pi -e 's/a/b/g' {} ;
ex)
find . -type f -name '*.html' -exec /usr/local/mysql/bin/replace myunggyu@orgio.net kang@dbakorea.pe.kr -- {} ;
ISO이미지 만들기
/down/Disk1 디렉토리의 내용을 Linux9i_1.iso라는 ISO이미지파일로 만든다.
mkisofs -r -o Linux9i_1.iso /down/Disk3
위에서 만들어진 Linux9i_1.iso파일을 레코더로 구울때
cdrecord -v -isosize speed=12 dev=0,0 Linux9i_1.iso
XMMS에서 한글출력
메뉴중 옵션-선택사항-폰트'에 다음과 같이 지정
옵션: 폰트셋 사용하기(멀티바이트 지원설정) 체크
연주목록에 다음과 같이 설정
-adobe-helvetica-bold-r-*-*-10-*, -baekmuk-gulimbdf-medium-r-normal-*-*-120-*-*-m-*-ksc5601.1987-0
기본창- X폰트사용 체크 하고 다음과 같이 설정
-adobe-helvetica-medium-r-*-*-8-*, -baekmuk-gulimbdf-medium-r-normal-*-*-120-*-*-m-*-ksc5601.1987-0
ISO파일 처리
CD이미지(ISO 9660) 만들기
dd if=/dev/cdrom of=ora817.iso
or
mkisofs -R -V Oracle817 -o ora817.iso /dev/cdrom
CD이미지(ISO 9660) 마운트
mount -r -t iso9660 -o loop ora817.iso /mnt/iso
CD이미지(ISO 9660) 굽기
cdrecord -scanbus로 가능한 dev파악
cdrecord -v -eject speed=12 dev=0,0,0 ora817.iso
file: 파일의 종류와 정보를 알려준다.
[kang@ns work]$ file signal_reset.c
signal_reset.c: C program text
[kang@ns work]$ file signal_reset
signal_reset: ELF 32-bit LSB executable, Intel 80386, version 1, dynamically linked (uses shared libs), not stripped
stat: Unix system함수인 stat(fstat)가 가지는 정보를 보여주기 위해 명령어로 구현되어진 것
[kang@ns work]$ stat signal_reset.c
File: "signal_reset.c"
Size: 175 Filetype: Regular File
Mode: (0664/-rw-rw-r--) Uid: ( 512/ kang) Gid: ( 512/ kang)
Device: 3,7 Inode: 96199 Links: 1
Access: Wed Oct 18 21:12:01 2000(00000.00:01:33)
Modify: Wed Oct 18 21:11:43 2000(00000.00:01:51)
Change: Wed Oct 18 21:11:43 2000(00000.00:01:51)
[kang@ns work]$ stat signal_reset
File: "signal_reset"
Size: 11991 Filetype: Regular File
Mode: (0775/-rwxrwxr-x) Uid: ( 512/ kang) Gid: ( 512/ kang)
Device: 3,7 Inode: 96198 Links: 1
Access: Wed Oct 18 21:12:06 2000(00000.00:01:30)
Modify: Wed Oct 18 21:11:50 2000(00000.00:01:46)
Change: Wed Oct 18 21:11:50 2000(00000.00:01:46)
reset: 키보드설정 reset(? 매뉴얼에도 없다. 잘모르겠다.)
[kang@ns work]$ reset
Erase is delete.
Kill is control-U (^U).
Interrupt is control-C (^C).
whatis : whatis데이터베이스에서 완전한 단어를 검색한다.
ex) whatis ls whereis
apropos : whatis데이터베이스에서 문자열을 검색한다. man -k와 같다.
ex) apropos socket
whereis : 바이너리,소스,매뉴얼 파일의 위치 출력
ex) whereis cp
cal : 달력 출력
ex) cal 2004 : 2004년 달력 출력
cal 5 2004 : 2004년 5월 달력 출력
tty : 자신이 사용하는 터미널명을 출력. kill명령으로 해당 터미널유저를 처리할때 쓰도록..
쉘에서...
?은 한문자를 의미
*은 모든 문자를 의미
ls dbakorea[0-9] : dbakorea0 ~ dbakorea9
ls dbakorea[09] : dbakorea0, dbakorea9
SORT
[kang@dbakorea test]$ cat sort.dat
aaa,강명규,관리자
ccc,홍길동,도둑놈
bbb,강감찬,장군
ddd,임꺽정,도적놈
[kang@dbakorea test]$ sort sort.dat
aaa,강명규,관리자
bbb,강감찬,장군
ccc,홍길동,도둑놈
ddd,임꺽정,도적놈
[kang@dbakorea test]$ sort -t , +1 sort.dat 2번째 컬럼을 기준으로 정렬. -t는 필드구분자로 콤마 지정
bbb,강감찬,장군
aaa,강명규,관리자
ddd,임꺽정,도적놈
ccc,홍길동,도둑놈
대소문자 변환
[kang@dbakorea test]$ tr "[a-z]" "[A-Z]" < sort.dat
AAA,강명규,관리자
CCC,홍길동,도둑놈
BBB,강감찬,장군
DDD,임꺽정,도적놈
PASTE
[kang@dbakorea test]$ cat > paste.data1
홍길동
이순신
김유신
[kang@dbakorea test]$ cat > paste.data2
부산
서울
대구
[kang@dbakorea test]$ paste paste.data1 paste.data2
홍길동 부산
이순신 서울
김유신 대구
[kang@dbakorea test]$ paste -d" " paste.data1 paste.data2
홍길동
부산
이순신
서울
김유신
대구
[kang@dbakorea test]$ paste -s -d":: " paste.data1
홍길동:이순신:김유신
[kang@dbakorea test]$
JOIN : DBMS의 조인기능과 유사
[kang@dbakorea test]$ cat > join.data1
maddog:강명규
gildong:홍길동
superman:슈퍼맨
batman:배트맨
[kang@dbakorea test]$ cat > join.data2
maddog:DBA
maddog:Programmer
superman:Hero
batman:American Hero
[kang@dbakorea test]$ join -j1 1 -j2 1 -t: join.data1 join.data2
maddog:강명규:DBA
maddog:강명규:Programmer
superman:슈퍼맨:Hero
[kang@dbakorea test]$
SPLIT
[kang@dbakorea test]$ split -100000 wf_cleaner_20040418.log wf_cleaner_
[kang@dbakorea test]$ ls -l
총 322816
-rw-r--r-- 1 sky other 82509153 4월 21일 16:15 wf_cleaner_20040418.log
-rw-r--r-- 1 sky other 4817168 4월 21일 16:16 wf_cleaner_aa
-rw-r--r-- 1 sky other 4826953 4월 21일 16:16 wf_cleaner_ab
-rw-r--r-- 1 sky other 4819016 4월 21일 16:16 wf_cleaner_ac
-rw-r--r-- 1 sky other 4818664 4월 21일 16:16 wf_cleaner_ad
-rw-r--r-- 1 sky other 4815234 4월 21일 16:16 wf_cleaner_ae
-rw-r--r-- 1 sky other 4826339 4월 21일 16:16 wf_cleaner_af
-rw-r--r-- 1 sky other 4822263 4월 21일 16:16 wf_cleaner_ag
-rw-r--r-- 1 sky other 4814657 4월 21일 16:16 wf_cleaner_ah
-rw-r--r-- 1 sky other 4816299 4월 21일 16:16 wf_cleaner_ai
-rw-r--r-- 1 sky other 4817442 4월 21일 16:16 wf_cleaner_aj
-rw-r--r-- 1 sky other 4807225 4월 21일 16:16 wf_cleaner_ak
-rw-r--r-- 1 sky other 4816881 4월 21일 16:16 wf_cleaner_al
-rw-r--r-- 1 sky other 4805557 4월 21일 16:16 wf_cleaner_am
-rw-r--r-- 1 sky other 4824945 4월 21일 16:16 wf_cleaner_an
-rw-r--r-- 1 sky other 4800172 4월 21일 16:16 wf_cleaner_ao
-rw-r--r-- 1 sky other 4813110 4월 21일 16:16 wf_cleaner_ap
-rw-r--r-- 1 sky other 4795892 4월 21일 16:16 wf_cleaner_aq
-rw-r--r-- 1 sky other 651336 4월 21일 16:16 wf_cleaner_ar
[kang@dbakorea test]$ cat wf_cleaner_a[a-r] > wf_cleaner_orig
[kang@dbakorea test]$
CUT : 컬럼단위 필터링 cf) grep은 행단위 필터링
필드,문자단위로 컬럼 출력
[kang@dbakorea test]$ cat sort.data
aaa,강명규,관리자
ccc,홍길동,도둑놈
bbb,강감찬,장군
ddd,임꺽정,도적놈
[kang@dbakorea test]$ cut -f1,3 -d , sort.data 1,3번째 필드만 출력. 필드구분자는 콤마
aaa,관리자
ccc,도둑놈
bbb,장군
ddd,도적놈
[kang@dbakorea test]$ cut -c5-7 sort.data 5~7컬럼값 출력
강명규
홍길동
강감찬
임꺽정
EGREP
grep과 달리 Regular Expression을 지원한다.
b : 일치되는 행의 블록 번호 출력
c : 문자열을 포함하는 행수 출력
h : 파일 이름을 출력하지 않음
i : 대소문자를 구별하지 않음
l : 문자열을 포함하는 파일 이름만 출력
n : 일치되는 행번호를 함께 출력
s : 오류가 발생할 경우에만 메시지 출력
v : 일치되지 않는 행만 출력
w : 문자열이 하나의 단어인 경우만 검색(grep만 가능)
e 표현식 : 정규 표현식이 - 문자로 시작할 때 유용
e 문자열 : fgrep에서만 사용, 문자열은 단순 문자열을 의미
f 파일명 : 검색문자열을 파일명으로 부터 받아들임
^ : 행의 시작
$ : 행의 끝
. : 임의의 한문자
[] : []속에 표현되는 문자 중 임의의 한 문자
* : * 앞의 정규표현식이 0회 이상 나타남
+ : + 앞의 정규표현식이 1회 이상 나타남(egrep에서만 가능)
? : ? 앞의 정규표현식이 0 또는 1회 나타남(egrep에서만 가능)
: 메타문자의 의미 제거(예 : '*'는 *문자를 의미)
| : 문자열간의 OR연산자(egrep에서만 가능)
() : 정규 표현식을 둘러 쌈(egrep에서만 가능)
[kang@dbakorea test]$ cat sort.data
aaa,강명규,관리자
ccc,홍길동,도둑놈
bbb,강감찬,장군
ddd,임꺽정,도적놈
[kang@dbakorea test]$ egrep '강명규|강감찬' sort.data
aaa,강명규,관리자
bbb,강감찬,장군
This article comes from dbakorea.pe.kr (Leave this line as is)
'Computing > Linux' 카테고리의 다른 글
| Subversion 사용 HOWTO (0) | 2007.09.04 |
|---|---|
| [펌] Qmail 메뉴얼 (1) | 2007.08.09 |
| 리눅스 프로그래머를 위한 가이드 (0) | 2007.08.08 |
| [펌] Linux 정리 #1 (0) | 2007.08.08 |
| tar 분할 압축하기 (4) | 2007.07.23 |
프로그램들이 시스템의 지원에 접근할 수 있도록 서비스를 제공하는 역할
※ version ex)2.4.17
2 : 획지적인 변화
4 : 짝수-안정, 홀수-개발버전
17 : 패치회수
== Grub(boot loader)
디스크상에서 커널의 물리적인 위치를 알 필요없이 단지 파일명과 커널이 위치하고 있는 파티션만 알고 있으면 커널을 로드할 수 있다.
※ /boot/grub/grub.conf
※ /dev/had의 MBR에 문제가 발생하면 /sbin/grub-install /dev/had로 GRUB를 인스톨 한다.
== 예약
# atq : <- /var/spool/at
# atrm at#
#crontab -l <- /var/spool/cron
#crontab -e
#crontab -r
※ #chsh :shell변경
== 정보보호 3대 목표
Confidential(기밀성) -> 군사, 암호학
Integrity(무결성) -> 금융, DB
Availity(가용성) -> IT, ERP
Accountability(책임추적성,책임추긍성) -> IT, Log
== Security
1. 물리적 통제
2. 논리적(기술적)
3. 관리적
4. BCP&DRP(Business Continuity Plan & Disaster Recovery Plan) - 업무에 대한 지속성 보장 계획 & 재난 복구 계획
== boot sequence
BIOS가 시스템 이상 여부 테스트
-> Booting 할 drive선택
-> 선택된 드라이브의 Master Boot Sector읽어들임
-> MBR이 파티션 테이블을 읽어 Booting할 파티션을 알아냄
-> Booting 파티션의 Boot Sector에 가지고 있는 프로그램이 해당 운영체제를 읽어들임
-> Kernel 압축해제
-> 장착된 Hardware검사, 장치 드라이버 설정
-> Kernel 이 '/'를 read-only로 mount
-> FileSystem검사
-> '/'를 read/write로 다시 mount
-> '/sbin/init' 실행(kernel이 최초로 실행하는 program으로 PID가 '1'
-> /etc/inittab에서 init실행을 위한 설정 내용 확인
-> /etc/rc.d/rc.syinit 실행(Hostname, Swapping, 시스템점검, 커널 모듈 로딩)
-> /etc/rc.d/rc 실행(inittab에 정의된 Default runlevel를 실행)
-> /etc/rc.d/rc.local (매버 실행할 내용을 넣어둠)
-> /etc/rc.d/rc.serial (시리얼 포트를 초기화한다)
-> login(getty) / X-Window(xfm)
※ /etc/inittab : sbin/init 실행을 위한 설정 내용 ->> init q (inittab설정 적용)
※ /etc/login.defs : 정책파일
== 시작 프로세스
# linuxconf <- X window
# ntsysv
# chkconfig --list service_name
# chkconfig --add service_name
# chkconfig --del service_name
# chkconfig [--level run_level] service_name <on|off|reset>
== 계정및 시스템 관리 보안
# pwunconv : shadow 에서 일반 패스워드로 전환
# pwconv : 일반 패스워드에서 shadow로 전환
== Network설정
#netconfig
#netcfg : Xwindow
※ /etc/sysconfig : booting시 참조되는 파일들
H/W, S/W, network설정, locale, firewall등읠 설정 파일들이 위치
ifconfig : Network Interface Card 설정, 수정, 상태
#ifconfig eth0 10.1.6.7.78 netmask 255.255.255.0 broadcast 10.1.6.255 up
#service network restart
※ /etc/hosts
※ /etc/syconfig/network-scripts/ifcfg-eth0(eth1) : ip
※ /etc/syconfig/network : gateway
※ /etc/resolv.conf
1. 설정tool이용(netconfig,netcfg)
2. prompt(ifconfig)
3. 설정파일 수동설정(/etc/syconfig/network-scripts/ifcfg-eth#)
※ /etc/rc.d/init.d/network : 시스템 부팅시 network를 구동
● nslookup, dig, host
● tcpdump : 특정 host에서 오는 packet dump
# tcpdump -x -X port 514 and host 10.1.6.71
== inetd daemon(<- /etc/hosts.allow, /etc/hosts.deny)
inetd : /etc/inetd.conf, /etc/serivces
tcpd : tcp wrapper
==> Xinetd(tcp,udp,(rpc)서비스에 대한 접근을 제어, tcp wrapper필요없음.)
/etc/xinetd.conf
- PAM package(/etc/pam.d/) : reference monitor
#vi /etc/pam.d/su : su제한
auth required /lib/security/$ISA/pam_wheel.so use_uid
#vi /etc/group : wheel그룹에 속한 user만이 su할수 있다
wheel:x:10:root,redhope
/etc/pam.d/login : 접속시간 제한(<- /etc/security/time.conf) p.157
== RPM
rpm -qa | grep tcpdump
== ssh
# ssh user_id@host : 이때 키는 데이터 암호화에 사용됨.
client : public key /$HOME/.ssh/unknown_host
server : private key /etc/ssh
# ssh-keygen -t rsa : 이때 키는 로그인에 사용됨.
/$HOME/.ssh/id_rsa : private key
/$HOME/.ssh/id_rsa.pub : public key
# scp id_rsa.pub test@10.1.6.99:~/.ssh/authorized_key2
● 시스템 관련 보안 설정
- /etc/securetty : 루트가 접속할 수 있는 터미널을 표시, 레드햇 리눅스에는 지역 가상 콘솔 (local virtual consoles: vtys)만을 기본 값으로 가지며 다른 원격 콘솔에서는 root로 접속하지 못하도록 한다.
- /etc/fstab : SUID/SGID 파일을 제한한다. 일반적으로 /var 파티션을 포함한 사용자의 홈 파티션에 "nosuid" 옵션을 설정한다.
- /etc/exports : 와일드카드를 사용하지 않도록 하며, 가능한 읽기 전용으로만 마운트하도록 한다.
- /etc/profile : 사용자의 파일생성 umask를 지정하며, 가능한 제한된 값으로 조정한다. 자주 쓰이는 값은 022, 033이고, 가장 제한적인 값은 077이다.
- /etc/pam.d/limits.comf: 파일시스템 제한을 설정할 수 있다. 기본 값인 "무제한"이 아닌 다른 값으로 설정하여 파일시스템의 사용을 제한한다.
- /etc/issue : telnet 등을 이용하여 시스템 버전 정보 유출을 방지한다.
- /etc/pam.d/login : .rhosts 파일을 사용하지 못하도록 한다.
● 네트워크 관련 보안 설정
네트워크 서비스는 주로 /etc/inetd.conf, /etc/services, /etc/rc.d/rcN.d(N은 시스템 런 레벨을 표시), 그리고 TCP-Wrapper의 설정 파일인 /etc/hosts.allow, /etc/hosts.deny 파일로 제어가 가능하다.
- /etc/inetd.conf : 불필요한 모든 네트워크 서비스들을 주석 처리하여 막도록 한다.
- /etc/rc.d/rcN.d : 시스템 시작시 실행되는 서버로 이 중 사용하지 않는(named, nfs 등) 서버를 삭제하도록 한다.
- /etc/services : 서비스를 주석 처리하거나 삭제할 수 있으나 보안에는 큰 영향을 미치지 않는다.
- /etc/hosts.allow : 네트워크 서비스에 접근할 필요가 있는 호스트를 등록한다.
- /etc/hosts.deny : ALL: ALL 로 설정하여 hosts.allow에서 허가한 호스트 이외의 모든 접근을 막는 것이 바람직하다.
- rpm -e : 레드햇에서 어떠한 패키지 전체를 삭제할 수 있는 명령
- dpkg : 데비안에서 어떠한 패키지 전체를 삭제할 수 있는 명령
-- Log관련
/etc/syslog.conf
/var/run/utmp : w,who
/var/log/wtmp : 성공한 로그인, 로그아웃 정보 - last [user_id]
/var/log/lastlog : 각 사용자의 최종기록 - lastlog [-u user_id]
/var/log/btmp : 실패한 로그인 (/var/log/btmp만들어주고 root,600 permission)
== ROOT만
chmod 600 /etc/inetd.conf
chown -R 700 /etc/rc.d/init.d/*
== Name Server
http://www.superuser.co.kr/dns/power-dns/page02_5_3.htm
Iterative 모드에서는
질의의 답을 모르면 알만한 다른 서버로 질의를 보내라고만 응답하기 때문에 자기는 응답에 대한 책임을 가지고 있지 않는다.
응답 가능한 NS의 목록을 전달한다.
Recursive 모드에서는
오직 실제 답과 에러 메시지만을 리턴 한다.
먼저 클라이언트는 로컬 네임 서버로 질의를 전달한다.
로컬 서버는 요청된 데이터를 도메인 내에서 찾으면 그에 해당하는 IP어드레스를 돌려주게 된다.
만약 로컬 네임 서버가 요청된 데이터를 찾지 못하면 다른 네임 서버로 질의를 전달한다.
최악의 경우 로컬 네임 서버의 질의는 DNS 트리의 최상위에 있는 루트 네임 서버에서 시작하여 요청된 데이터가 발견될 때까지 아래로 전달되게 된다
# nslookup -sil
> set type=any
# dig ns.dankook.ac.kr
# dig @ns.dankook.ac.kr dankook.ac.kr axfr
- Forwaard DNS Zone file
/var/named : localhost.zone named.ca named.local
#cp localhost.zone ilovekorea.com.zone
#vi /var/named/ilovekorea.com.zone
- RR의 종류들
domain이름이나 hostname은 여러종류의 속성을 가질수 있다.
SOA(Start of Authority) domain 권한의 시작을 알려주고 slave dns서버와 zone동기화 schedule들, TTL값을 소개
NS(Name Server)
MX(mail exchanger):mail server지정
A(Address)우측에 IP가 옴(A속성외에 IP가 오는 경우는 없음), (domain, hostname을 ip로 번역:forward lookup)
IN(Internet Class)
CNAME(CANOCICAL NAME정의:별명설정시 사용) ex) web IN CNAME www.hrd.co.kr.
- reverse lookup시 PTR(Pointer:A속성이랑 반대로 ip->hostname찾을때)사용
#cp named.local 2.68.192.rzone
#vi /var/named/2.68.192.rzone
78 IN PTR hrd78.hpec.co.kr.
- zone transfer 제어
#vi /etc/named.conf의 options에서
allow-transfer { 10.1.6.78; };
allow-transfer { 10.1.6.0/24; };
allow-transfer { none; };
- allow-update
/etc/named.conf에서
zone "redhope.com" IN {
type master;
file "redhope.com.zone";
allow-update { 10.1.6.78; };
};
일 경우
#nsupdate
>prereq nxdomain linux.redhope.com.
>update add linux.redhope.com. 300 A 10.1.6.77
>
- reverse-dns
/etc/named.conf에서
zone "6.1.10.in-addr.arpa" IN {
type master;
file "redhope.com.rev";
allow-update { none; };
};
== NameServer 확인
1. name server 등록
#vi /etc/resolv.conf
namesesrver 10.1.6.##
2. restart network
#/etc/init.d/network restart (service network restart)
3. restart named
#/etc/init.d/named restart (service named restart)
4. 확인
#nslookup
>one.com
..
>192.168.1.##
..
>set q=mx
>one.com
..
>set q=ns
>one.com
..
== IPtables <- kernel 2.4
/etc/sysconfig/iptables
ipchains(2.2), ipfwadm(2.0)
3개의 테이블(default(filter), nat(network address trasration),mangle)
5개의 chain(INPUT, FORWARD, OUTPUT, PREROUTING, POSTROUTING) <- filtering
PREROUTING : INPUT 이전에 <- proxy
POSTROUTING : INPUT 이후에 <-
iptables
tcp_wrappers
# iptables -L
# iptables -L -t nat : 주소전환이 필요할때
# iptables -L -t mangle : 부가적 제어할때
# iptables -P INPUT DROP : input policy change
# iptables -P INPUT ACCEPT
# iptables -A INPUT -s 10.1.6.0/24 -d 10.1.6.0/24 -j ACCEPT
# iptables -A INPUT -s 10.1.6.0/24 -d 10.1.6.0/24 -j DROP
# iptables -D INPUT -s 10.1.6.0/24 -d 10.1.6.0/24 -j ACCEPT
# iptables -D INPUT ACCEPT 1
# iptables-save > /etc/sysconfig/iptables : 설정된 내용을 file 화
# iptables -t nat -A POSTROUTING -s 10.1.6.0/24 -d 0.0.0.0/0 -j MASQUERADE
/proc/sys/ : kernel dump file system
/etc/sysctl.conf : kernel parameter control
# sysctl -p
== MASQUERADE Setting(사설IP에서 인터넷 가능하게 하기)
1. eth0 - 10.1.6.78, eth0:0 - 192.168.0.254
2. routing table에 외부 gateway추가
3. /etc/sysctl.conf 에서 net.ipv4.ip_forward = 0 : routing available
4. # iptables -t nat -A POSTROUTING -s 10.1.6.0/24 -d 0.0.0.0/0 -j MASQUERADE
# ifconfig eth0 192.168.0.254
# ifconfig eth0:0 10.1.6.78
# route add default gw 10.1.6.254
# vi /etc/sysctl.conf
net.ipv4.ip_forward = 1
# iptables -t nat -A POSTROUTING -s 192.168.5.0/24 -d 0.0.0.0/0 -j MASQUERADE
========== 가상호스트/Redirect
아래의 예는 dbakorea.pe.kr로 오면, www.dbakorea.pe.kr로 redirect시킨다.
본인은 아파치말고, packet filtering으로 처리하려했으나 실력부족과 게으름으로 인해
그만두었다.
ServerName dbakorea.pe.kr
Redirect / http://www.dbakorea.pe.kr
<VirtualHost 여긴아이피>
ServerName aaaa.co.kr
ServerAlias www.aaaa.co.kr bbbb.co.kr www.bbbb.co.kr
Redirect / http://aaaa.com
</VirtualHost>
============ 가상호스트의 전형적인예
ServerAdmin kang@dbakorea.pe.kr
DocumentRoot /webhosting/dbakorea-mobile
ServerName mobile.dbakorea.pe.kr
ErrorLog /usr/local/apache/logs/mobile.dbakorea.pe.kr-error_log
CustomLog /usr/local/apache/logs/mobile.dbakorea.pe.kr-access_log common
ScriptAlias /cgi-bin/ /webhosting/dbakorea-mobile/cgi-bin/
DirectoryIndex login.html
자주쓰는 명령어 모음
공사중에 로그인 막기
시스템을 공사중일 때, root 이외의 다른 사용자를 로그인 못하게 해야 할 때가 있죠?
그럴 때는, /etc/nologin 이라는 파일을 만들어,
공사중 또는 Under Construction이라는 공지를 넣으면 됩니다.
크기가 가장 큰 파일, 디렉토리 찾기
가장 큰 디렉토리를 찾으려면,
du -S | sort -n
cf) 솔라리스의 경우
du -sk `ls -1 | grep '/$'`|sort +n
가장 큰 파일을 찾으려면,
ls -lR | sort +4n
디스크 Full발생시 쓸모없는 파일 제거
오브젝트파일만 제거하는 예제
find . -name '*.o' -print -exec rm -f {} ;
실행파일들 출력
find . -type f -perm +u+x -print
find의 일반적인 용례
name 파일명 지정한 파일명에 해당하는 파일을 검색
메타문자를 사용할 경우 파일명을 ''기호 내에 기입
-size 파일 크기 지정된 크기의 파일을 검색. 크기는 블록 단위, 1 블록 = 512 바이트
-mtime 숫자 지정된 날짜 이전에 수정된 파일을 검색
-ctime 숫자 가장 최근에 변경된 것이 지정된 날짜 전인 파일 검색
-user 사용자명 지정된 사용자 수용의 파일 검색
-print 검색 결과를 화면에 표시
-atime 숫자 지정된 날짜 이전에 접근 된 파일을 검색
-perm 접근권한 지정
-type 파일 유형 지정된 유형의 파일을 검색
b: 블록 특수 파일
c: 문자 특수 파일
d: 디렉토리
f: 일반파일
l: 링크파일
p: 파이프 파일
-exec 명령어 {} ;
실행 결과를 입력 파일로 받아들여 명령어 실행.
명령어의 끝은 ;
{} : 현재 경로명으로 대치
현재 디렉토리의 크기만을 파악할때
[root@dev2 local]# du -c -h --max-depth=0 *
6.4M apache
35M bin
43M dns
1.7M doc
42k etc
1.0k games
42k geektalkd
1.1M gnuws
1.1M include
41k info
19M jakarta-tomcat-3.2.3
0 jre
15M jre118_v3
25M lib
62k libexec
1011k man
1.3M mm.mysql.jdbc-1.2c
937k sbin
3.8M share
1.8M shoutcast-1-8-3-linux-glibc6
5.2M ssl
159M total
시스템 정보 감추기
/etc/inetd.conf 파일을 열어서,
telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd -h
어떤 프로세스가 메모리를 가장 많이 잡아먹고 있는지 알아내기
ps -aux | sort +4n
또는
ps -aux | sort +5n
FTP로 들어온 사용자 확인하기
ftpwho
ftpcount
원하지 않는 사용자 죽이기
[root@dream /root]# skill -KILL sunny
위의 명령을 내리면 sunny 라는 사용자를 완전히 추방시킬수 있습니다.
그런데 이렇게 완전히 추방시키는게 아니구, 특정 터미널에 접속해있는 사용자만 추방시켜야 할 때도 있겠죠?
그럴때는
[root@dream /root]# skill -KILL -v pts/14
이런식으로 하면 된다 그럼 pts/14 에 연결되어 있는 사용자가 죽게 됩니다.
less 결과를 vi로 보기
less상태에서 v를 누르면 바로 vi로 감
vi에서 블럭 설정하기
alt+v 하면, 라인 단위로 블럭 설정을 할 수 있으며, 해제 하시려면 Esc를 누르면 됩니다.
또한 ctl+v를 하시면, 블럭 단위로 블럭을 설정하실 수 있습니다.
블럭을 설정 하신 뒤,
삭제를 하려면 x
복사를 하려면 y
붙여넣기는 p
man 페이지 프린트하기
vi에 대한 매뉴얼을 ps(postscript파일)로 저장
man -t vi > vi.ps
man 페이지를 일반파일로 갈무리하려면 man vi | col -b > aa.txt
ping 무시하기
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
echo 0 > /proc/sys/net/ipv4/icmp_echo_ignore_all
동시에 여러개의 하위 디렉토리 만들기
mkdir -p music/koreanmusic/ost
리로 다시 살리기
boot : vmlinuz root=/dev/hda6
특정 사용자 ftp 접근 막기
/etc/ftpusers 파일에 로그인 네임을 추가하면 됩니다.
'Computing > Linux' 카테고리의 다른 글
| Subversion 사용 HOWTO (0) | 2007.09.04 |
|---|---|
| [펌] Qmail 메뉴얼 (1) | 2007.08.09 |
| 리눅스 프로그래머를 위한 가이드 (0) | 2007.08.08 |
| [펌] Linux 정리 #2 (0) | 2007.08.08 |
| tar 분할 압축하기 (4) | 2007.07.23 |
결국 복구는 했지만 백업화일을 만들어 두지 않아서 나름 귀찮고 힘든 과정이었다.
그래서 mysql 를 날렸을때 복구하는 방법을 간단하게나마 설명하고자 한다.
root 계정으로 작업하고 /usr/local/mysql 을 기본 디렉토리로 본다는 가정하에.. ^^
mysqldump를 이용한 백업화일이 존재하는 경우
/usr/local/mysql/bin/mysql -u root -p < BackUp.sql
가장 쉽게 복구하는 방법이다.
하지만 이 경우 문제점이 있다.
Cron 등의 프로그램으로 매일 백업을 받는다고 하더라도...
백업받은 시점과 DB를 날린 시점에서의 데이터는 다를수 있기 때문이다.
그런 부분을 커버 할수 있는것이 binlog 이다.
원래 binlog는 replication 을 위한 것인데... replication 이 아닌 복구용도로도 훌륭한 데이터이다.
/etc/my.cnf 에..
log-bin 라는 부분이 주석처리 되어 있지않으면..
mysql 은 기본적으로 /usr/local/mysql/data 디렉토리에 Host명-bin.000001 Host명-bin.000002 .... 과 같은
형식으로 만들어 질것이다. mysql을 재시작할때마다 Host명-bin.0000001 에서 숫자부분이 늘어난 화일이
생성되며 그 화일에 새롭게 기록한다.
※ mysql binlog 디렉토리 설정
my.cnf 에서
log_bin = /usr/local/mysql/data/mysql-bin.log <== 이런식의 설정도 가능하다.
bin 로그에는 기본적으로 DDL(Create, Alter, Drop)문과 DML중 Insert Update Delect 문등이 기록되는데..
이 기록들은 기본적으로 데이터에 변화를 주는 SQL문들이다..
bin 로그를 보려면 log의 데이터를변환해야한다.
binlog는 기본적으로 바이너리로 되어 있기에 텍스트 형태로 푸는 과정이 필요하다.
/usr/local/mysql/bin/mysqlbinlog /usr/local/mysql/data/Host명-bin.000001 >> 1.sql
이와 같은 과정으로 모든 binlog를 푼다..
vi 등으로 보면 시간 및 각각의 sql문들이 보일것이다..
※ 로그화일 쪼개기
가끔 log 화일이 너무 커서 제대로 인식이 안되는 경우가 있다.
이런 경우 split 이라는 훌륭한 툴이 있다.
split -l 100000 1.sql
10만 라인별로 1.sql 을 xaa, xab, aac..... 순으로 화일이 생성되면서 짜른다.
자 이제 복구를 하자라고 하고 싶지만..
여기서 주의 할것이 있다..
처음에... drop database 같은 sql 을 날렸다면
이 역시 binlog에 포함되어 있을것이다.
맨 마지막 로그 화일을 열어서 그부분을 삭제 또는 주석처리하자..
그렇지 않으면 애써 복구한것을 마지막에 다시 또 날리는 되는 결과를 .....
이제서야 복구를 할수 있을것이다.
/usr/local/mysql/bin/mysql -u root -p < 1.sql
만약 여기서도 5만줄쯤에서 오류가 났다라고 한다면...
1.sql 에서 1~49999 까지는 실행이 되었다.
그러므로 1~49999 를 삭제(vi 로 연다음 d49999 이라고 입력하고 Enter ...)한다.
그리고 문제가 되는 첫줄(1~49999를 삭제하기전에는 오류가 난 5만번째라인)의 SQL 부분을 해결한다음...
저장....
그리고 다시 복구과정을 반복
/usr/local/mysql/bin/mysql -u root -p < 1.sql
php 스쿨 [서버운영] Drop 된 Mysql Binlog를 이용한 복구 과정 에서 퍼 왔습니다.
'Computing > MySQL' 카테고리의 다른 글
| mysql 복구 (0) | 2011.11.04 |
|---|---|
| [Mysql] 쿼리문 내에서 encoding 변경... (0) | 2010.11.17 |
| [펌]MySQL Cluster (0) | 2007.07.25 |
| [펌]MySQL Replication 설치 (3) | 2007.07.25 |
MySQL Cluster
저작권:이 문서는 자유롭게 배포가 가능합니다. 단 상업적 용도로 사용할 수 없습니다.
배포 시 작성자의 이름 및 출처를 꼭 명시하기 바랍니다.
작성자 : f405(ccotti22)
작성일 : 2005년 8월 10일 수요일
이메일 : f405@naver.com
홈페이지 : http://f405.tistory.com
이 문서는 MySQL Cluster 매뉴얼을 번역, 정리한 것으로 틀린 부분을 다소 포함할 수 있으며, 저는 그에 대한 책임을 지지 않겠습니다.
부족하지만 다른 분들도 공부하는데 도움이 되길 바랍니다.
그리고 이 문서를 작성하기 전 참고한 리눅스 및 MySQL 문서들을 작성하신 많은 선배님들에게 감사의 말씀을 드립니다.
그리고 이 후부터는 경어는 생략하였습니다. 양해의 말씀을...
Introduction
MySQL 클러스터는 분산 컴퓨팅 환경에서 high-availability와 high-redundancy를 채택하였다. MySQL 클러스터는 NDB 클러스터 스토리지 엔진을 사용하여, 클러스터에서 여러 개의 서버가 함께 돌아가도록 한다. MySQL 클러스터가 지원하는 운영 체제는 Linux, Mac OS X, Solaris 등 이다. 더 자세한 정보는 다음 사이트를 참고 하길 바란다.
http://www.mysql.com/products/cluster
1. MySQL Cluster Overview
MySQL 클러스터는 share-nothing 시스템에서 in-memory 데이터 베이스의 클러스터링을 가능하게 한다. 이러한 아키텍쳐는 특정한 하드웨어 및 소프트웨어를 요구하지 않으므로 비용을 절감할 수 있도록 하며, 각 콤포넌트가 고유 메모리와 디스크를 보유함으로 단일 취약점(single point of failure)을 가지지 않는다.

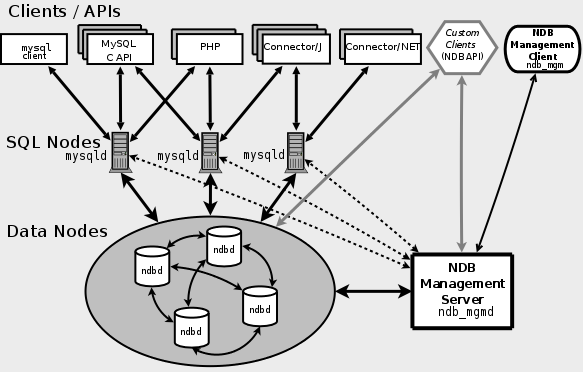
2. Basic MySQL Cluster Concepts
NDB는 높은 가용성과 데이터 지속성을 갖는 인 메모리 스토리지 엔진이다. DB 스토리지 는 failover와 로드 밸런싱 옵션을 설정할 수 있다. MySQL 클러스터는 NDB 스토리지 엔진과 MySQL 서버로 구성되어 있으며, MySQL 클러스터의 클러스터 부분은 MySQL 서버에 독립적이다. MySQL 클러스터의 각 부분은 노드로 간주한다.
"노드"는 일반적으로 컴퓨터를 지칭하지만 MySQL 클러스터에서는 "프로세스"를 말한다.
- MGM node : 이 노드는 설정을 포함, 다른 노드를 관리하는 매니저 노드이다.
다른 노드보다 가장 먼저 실행되며 ndb_mgmd 명령으로 실행시킨다.
- data node : 클러스터의 데이터를 저장하는 노드이다.
ndbd 명령으로 실행시킨다.
- SQL node : 클러스터 데이터에 접근하는 노드이다.
MySQL 클러스터에서는 NDB 클러스터 스토리지 엔진을 사용하는
MySQL 서버가 클라이언트 노드이다.
mysqld --ndbcluster나 mysqld 명령으로 실행시키는데,
이 때는 my.cnf 에 ndbcluster를 추가한다.
Simple Multi-Computer How-To
다음과 같이 4대의 컴퓨터로 클러스터를 구성하는 것을 가정하고 있다. (4개의 노드로 구성되고, 각각의 노드는 편이성을 위해 IP로 지칭한다.)
|
Node |
IP Address |
|
Management (MGM) node |
192.168.0.10 |
|
MySQL server (SQL) node |
192.168.0.20 |
|
Data (NDBD) node "A" |
192.168.0.30 |
|
Data (NDBD) node "B" |
192.168.0.40 |

설치 및 사용 시 주의할 점은 MySQL 클러스터는 클러스터 노드 간 커뮤니케이션에 암호화 및 보호 장치가 전혀 없으므로, 웹 상에서 사용하려면 방화벽을 사용하는 등의 보안상의 대책이 필요하다는 것이다.
MySQL Cluster를 사용하기 위해서는 -max 버전을 설치해야 한다.
모든 설치는 root권한으로 진행하며 작업에 필요한 파일은 /usr/local/ 에 저장한다.
# cd /usr/local
# groupadd mysql
# useradd -g mysql mysql
# tar -xzvf mysql-max-4.1.13-pc-linux-gnu-i686.tar.gz
# ln -s /usr/local/ mysql-max-4.1.13-pc-linux-gnu-i686 mysql
# cd mysql
# scripts/mysql_install_db --user=mysql
# chown -R root .
# chown -R mysql data
# chgrp -R mysql .
5. 시스템 부팅 시 자동적으로 Mysql을 실행할 수 있도록 설정한다.
# cp support-files/mysql.server /etc/rc.d/init.d/
# chmod +x /etc/rc.d/init.d/mysql.server
# chkconfig --add mysql.server
6. MGM (management) 노드를 별도의 PC에 설치할 경우 mysql 데몬은 설치하지 않아도 무방하다. 위와 같이 설치한 후 MGM 서버는 다음과 같이 설치를 계속한다.
# cd /usr/local/mysql/bin/
# cp ndb_mgm* /usr/local/bin/
# chmod +x ndb_mgm*
# vi /etc/my.cnf
[MYSQLD] # Options for mysqld process:
Ndbcluster # run NDB enginen
db-connectstring=192.168.0.10 # location of MGM node
[MYSQL_CLUSTER] # Options for ndbd process:
ndb-connectstring=192.168.0.10 # location of MGM node
# mkdir /var/lib/mysql-cluster# cd /var/lib/mysql-cluster
# vi config.ini
[NDBD DEFAULT] # Options affecting ndbd processes on all data nodes:
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough
# for this example Cluster setup.
[TCP DEFAULT] # TCP/IP options:portnumber=2202
# This the default; however, you can use any
# port that is free for all the hosts in cluster
# Note: In MySQL 5.0, this parameter is deprecated;
# it is recommended that you do not specify the
# portnumber at all and simply allow the port to be
# allocated automatically
[NDB_MGMD] # Management process options:
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node logfiles
[NDBD] # Options for data node "A":
# (one [NDBD] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's
# datafiles
[NDBD] # Options for data node "B":
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's
# datafiles
[MYSQLD] # SQL node options:
hostname=192.168.0.20 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for SQL node's datafiles
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
# ndb_mgmd -f /var/lib/mysql-cluster/config.iniMGM 노드를 다운시킬 때에는 다음과 같이 하면 된다.
# ndb_mgm -e shutdown
# ndbd --initial
# /etc/rc.d/init.d/mysql.server start
# ndb_mgm
-- NDB Cluster -- Management Client --
ndb_mgm>
ndb_mgm> show
Connected to Management Server at: 192.168.0.10:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.30 (Version: 4.1.13, Nodegroup: 0, Master)
id=3 @192.168.0.40 (Version: 4.1.13, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.10 (Version: 4.1.13)
[mysqld(API)] 1 node(s)
id=4 (Version: 4.1.13)
ndb_mgm>
3. MySQL 클러스터의 제한
- 트랙잭션 수행 중의 롤백을 지원하지 않으므로, 작업 수행 중에 문제가 발생하였다면, 전체 트랙잭션 이전으로 롤백하여야 한다.
- 실제 논리적인 메모리의 한계는 없으므로 물리적으로 허용하는 만큼 메모리를 설정하는 것이 가능하다.
- 컬럼 명의 길이는 31자, 데이터베이스와 테이블 명은 122자까지 길이가 제한된다. 데이터베이스 테이블, 시스템 테이블, BLOB인덱스를 포함한 메타 데이터(속성정보)는 1600개까지만 가능하다.
- 클러스터에서 생성할 수 있는 테이블 수는 최대 128개이다.
- 하나의 로우 전체 크기가 8KB가 최대이다(BLOB를 포함하지 않은 경우).
- 테이블의 Key는 32개가 최대이다.
- 모든 클러스터의 기종은 동일해야 한다. 기종에 따른 비트저장방식이 다른 경우에 문제가 발생하기 때문이다.
- 운영 중 스키마 변경이 불가능하다.
- 운영 중 노드를 추가하거나 삭제할 수 없다.
- 최대 데이터 노드의 수는 48개이다.
- 모든 노드는 63개가 최대이다. (SQL node, Data node, 매니저를 포함)
4. MySQL Cluster FAQ
(SizeofDatabase * NumberOfReplicas * 1.1 ) / NumberOfDataNodes
5. MySQL Cluster Glossary
- ndbd : 데이터 노드 데몬
- ndb_mgmd : MGM서버 데몬
- ndb_mgm : MGM 클라이언트
- ndb_waiter : 클러스터의 모든 노드들의 상태를 확인할 때 사용
- ndb_restore : 백업으로부터 클러스터의 데이터를 복구할 때 사용
이미지 #1
첫번째 이미지
이미지 #2
두번째이미지
'Computing > MySQL' 카테고리의 다른 글
| mysql 복구 (0) | 2011.11.04 |
|---|---|
| [Mysql] 쿼리문 내에서 encoding 변경... (0) | 2010.11.17 |
| [펌]MySql 복구 방법 (0) | 2007.07.25 |
| [펌]MySQL Replication 설치 (3) | 2007.07.25 |